agent有感1:claude code/codex/opencode
最近几天玩了玩三个AI智能体(英文称之为AI Agent)——claude code/codex/opencode,有些体会,作文分享。
推出时间
cc于25年2月推出;codex于25年4月推出;opencode于25年5月推出,是cc/codex的开源平替。
这仨都在25年下半年越来越火。我们可以在 https://www.star-history.com 查看他们走红的时间。
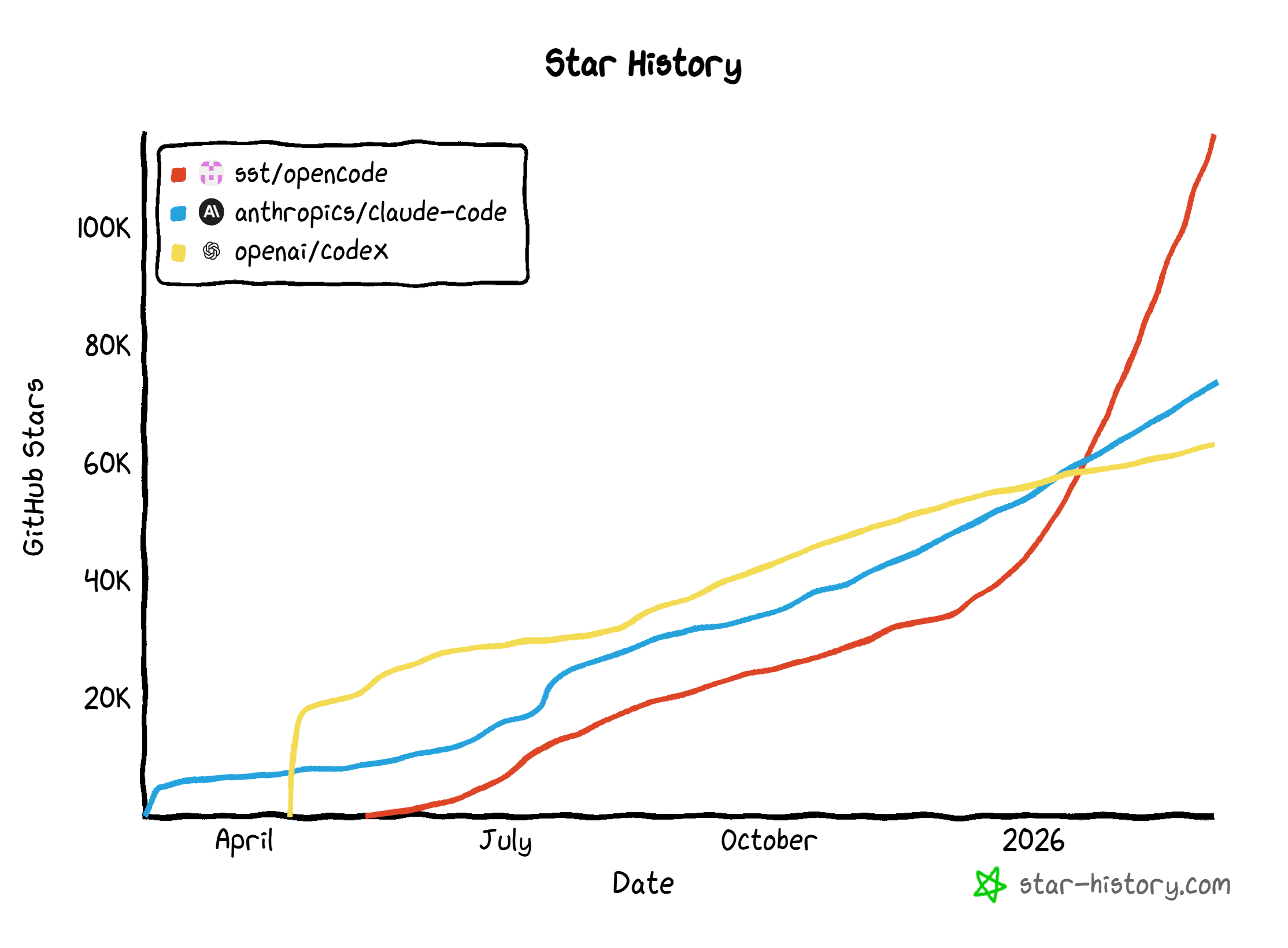
注:openai 2021年为初版GitHub Copilot训练了一个名为”codex”的模型(对GPT-3微调得到的),在2025年4月又推出了一个名为”codex”的在命令行中运行的软件。两者不是一个东西。
类似物
它们类似于vscode/cursor的agent模式,但能跑更长时间,使用方式更极简。
危险程度排行
众所周知,agent是十分危险的,无论是对个人还是对全人类。轻则删库删文件,重可。。。(自行联想)
如果对现在的AI做一个危险程度排行,我认为:问答式<vscode/cursor的agent模式<cc/codex。
问答式AI,最危险的情况无非是散布谣言、忽悠一大批人,这种事古已有之,不怕。
25年春夏,Bengio曾希望用问答式AI(他称之为Scientist AI)来控制Agent AI。这可能是低级智能控制高级智能的唯一方法。
学到东西排行
cc/codex是不利于学习的。我可以用它俩帮我复现一篇文章,但我会对这篇文章一无所知。我也可以用它们帮我写出vit或mamba,但我也会对它们一无所知。
学到东西排行:问答式>vs code/cursor 的agent模式>cc/codex。
我认为,至少目前,人参与得越多,学到的东西越多,危险程度越小。
运行时间排行
毫无疑问,问答式>vs code/cursor 的agent模式>cc/codex。
科研与工程
如果你发明了一个新算法,或者用ai证明了某个数学难题,本着负责任的态度,你应当一行一行看。
但对于工程问题,cc/codex是可用的,因为你可以根据他们给出的定量指标来判断对错。
维护困难
cc/codex当然有很高的商业价值,也带来很多机遇。现在我奶奶都可以用它们都可以写网页、APP、软件。只不过后续维护很困难。
提示词
23年秋gpt-store发布时(第一届openai开发者大会),我曾以为它也能改变世界,结果并没有。我用了快一年,后来用得越来越少,直到彻底不用。
究其原因,它不过是相当于多写了一轮提示词。那我为什么不直接多写一轮提示词呢?
现在anthropic推出的所谓的MCP和skills,无非也是多写一轮提示词罢了。
但是,要注意,GPT-Store是和问答式AI绑定的, mcp和skills是和agent AI绑定的,因此或许后者可以超越前者。
工作流
cc/codex 对于工作流可能带来颠覆。
比如,我之前用AI做PPT,需要先用问答式AI写提示词,再把提示词教给gamma这样专门生成PPT的AI。现在直接用它们就行了。而且,前者没法迭代,后者可以。
这里的关键是:安全对你的工作到底有多重要?如果改错了对你影响大不大?需不需要你自己去检查它们的修改?
如果你的回答是:非常重要、非常大、需要,那么它们对你的帮助可能不大。
多智能体协作
opencode丝毫不虚cc/codex。开源好处之一是有很多人无偿支持。这不,有一个很好用的插件叫oh-my-opencode,发明者搞了7个智能体协同工作。这东西很不错,很可能改变世界。
多智能体协作这事古已有之。24年的alpha geometry, 22年年初的instruct gpt, 甚至14年的GAN,称得上是广义的多智能体协作。但在AI Agent时代它可能会大放异彩。
编程、数学、物理
编程
上述内容都是AI在编程上的进步。其实从2022年11月ChatGPT发布的那天,大家就应该想到会有今天的结局。当年的ChatGPT就可以5分钟用5种方法实现svm,那今天的这些又有什么可让人惊讶的呢?
数学
和编程一样,数学也是标签非常明确的任务,很适合测试AI,我很喜欢。
据我所知,目前有6个自然语言模型可以达到IMO Gold的水平:
| 序号 | 模型名称 | 开发机构 | 发布时间 | 论文链接 | 开源状态 | 模型链接 |
|---|---|---|---|---|---|---|
| 1 | - | OpenAI | 2025年7月 | - | × 封闭权重 | - |
| 2 | - | 2025年7月 | - | × 封闭权重 | - | |
| 3 | DeepSeek-Math-V2 | DeepSeek | 2025年11月 | 2511.22570 | ✓ 开放权重 | Hugging Face |
| 4 | DeepSeek-V3.2-Speciale | DeepSeek | 2025年12月 | 2512.02556 | ✓ 开放权重 | Hugging Face |
| 5 | Aletheia | 2026年2月 | 2602.10177 | × 封闭权重 | - | |
| 6 | Ring-2.5-1T | Inclusion AI | 2026年2月 | - | ✓ 开放权重 | Hugging Face |
但是OpenAI和Google完全不提他们是怎么做到的,而DeepSeek的文章写得很详尽。我相信公道自在人心。
多智能体协作应可以帮助人类达到IMO第一的水平,现在只有一步之遥。gpt-o1发布的那天就注定如此了,因为它五分钟就能解决五道本科水平的数学题。
下一步则是超越人类,去证明人类不曾证明的重要的数学题。注意是重要难题,而不是边角料和小鱼小虾。
这点未必能做到。毕竟IMO只是高中水平的数学比赛。
物理
大语言模型,在编程、数学、语文上都展现出了极强的能力。但是他的物理水平也就那么回事儿。他可以拿到IMO金牌,但是却并不能给你讲清楚,地球如果不自转绕着太阳是平动还是转动;也不能说明白,为什么伽利略用脉搏测单摆周期而桑托里奥用单摆周期测脉搏,物理学家却认为他俩都是对的。
许多学者渴望的 世界模型/具身智能 是一个真正理解物理的AI。这点也未必能做到。
为什么大语言模型在数学会比物理先成功呢?
我想到两个原因,第一,数学更适合用语言来描述,相比物理,故而训练数据上前者远比后者多。第二,数学是极端严谨的,物理则是介于严谨和不严谨之间的,这就是说,对于前者,大语言模型可以得到一个明确的label,从而有明确的反馈。
有一个很有名的物理学家曾经对学生说,不要问我质量是怎么定义的,电荷是怎么定义的,在物理学里我们没法精确的定义任何东西,当我说一件事情,你大约知道我在说什么,当你说一件事情,我也大约知道你在说什么,这就足够了。
多智能体协作或可对理解物理有些帮助。
付费
订阅上,我为OpenAI, Github Copilot, Sider付费较多。
API上,我为DeepSeek, Kimi付费较多。
这些钱我觉得都很值。
专用、通用
cc/codex达到通用人工智能了吗?
2023年11月,谷歌写了篇论文,名为 *Levels of AGI for Operationalizing Progress on the Path to AGI*,分析专用人工智能和通用人工智能都做到什么程度,表一如下:
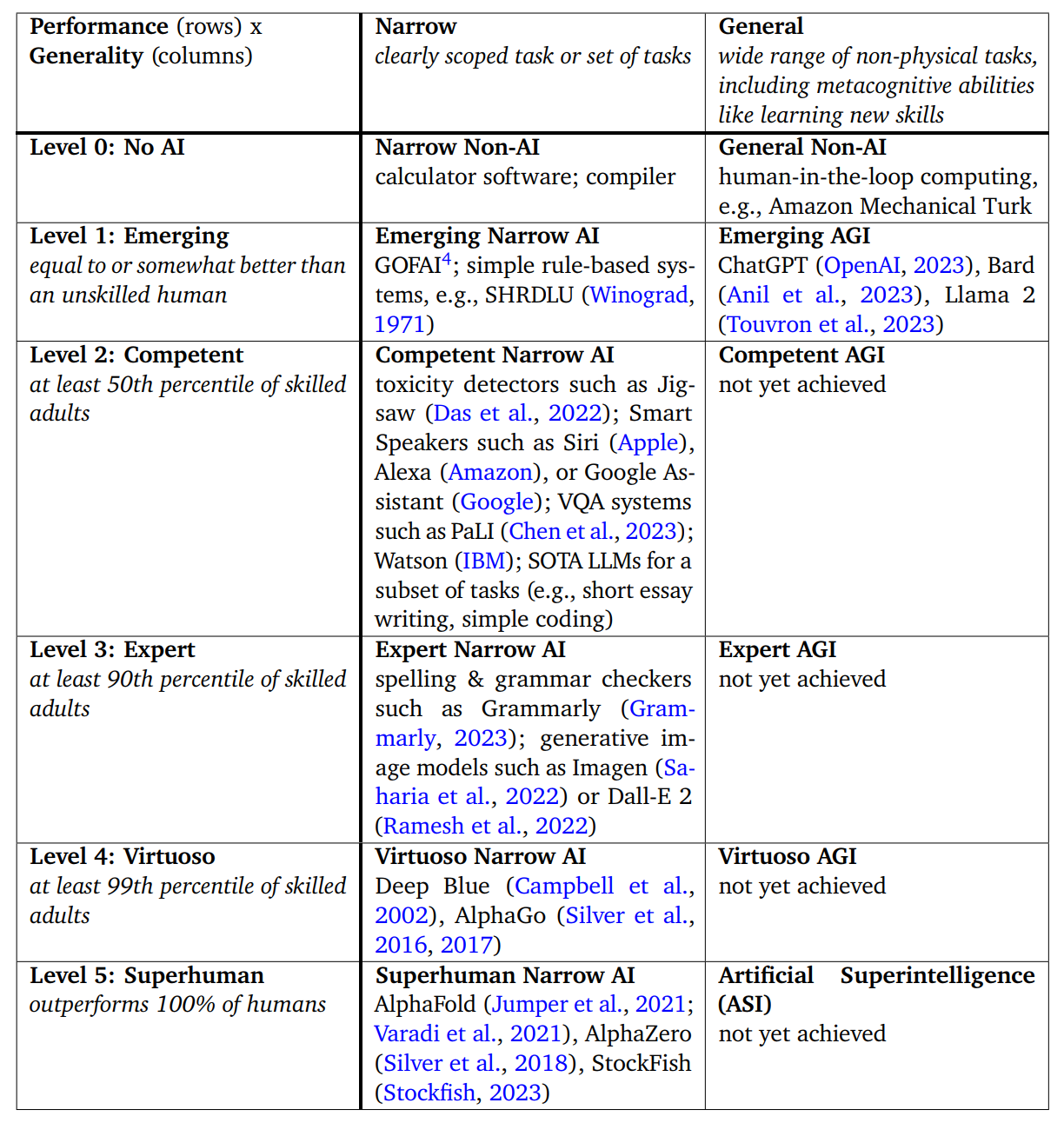
这张表对5个等级的定义,我认为是合理的。
o1/o3、cc/codex,厉害归厉害,但是不能给你倒杯水,也不能操纵机械臂倒水,也不能给你炒盘菜,那肯定排不到通用level2。换句话说,2022年RLHF、2024年chain of thought、2025年agent的突破都达不到谷歌这篇论文里的通用level2。
我认为可以再加一列:文字相关任务。
语文、数学、代码,均为文字。
| Level | 专用(Narrow) | 文字相关任务(Literate) | 通用(General) |
|---|---|---|---|
| 0 | 无AI | 无AI | 无AI |
| 1 涌现 | 早期专家系统 | GPT-1, GPT-2, GPT-3 | GPT-3.5, GPT-o1, Claude Code |
| 2 有能力 (>50% 专业人士) | Siri, Alexa, 智能助手 | GPT-3.5, GPT-4 | 尚未实现 |
| 3 专家 (>90% 专业人士) | DALL-E 2, Grammarly | GPT-o1, DeepSeek-R1 | 尚未实现 |
| 4 大师 (>99% 专业人士) | 深蓝, AlphaGo | Claude Code/Codex/Opencode | 尚未实现 |
| 5 超人类 (>100% 专业人士) | AlphaFold, AlphaZero, StockFish | 尚未实现 | 尚未实现 |
Human Last Exam
Human Last Exam, HLE 可以看成文字相关任务4或5的水平。它不是通用的。
翻译软件
2024年12月,我写下:我认为深度学习是欧几里得、伽利略之后的第三次科学革命。大意是,深度学习可以充当人类和自然界(特别是复杂系统)的“翻译软件”。
这里有件事需要考虑一下——“翻译软件”要打造成专用还是通用的?
我现在的想法是:
- 对于文字无关的任务(例如,解码EEG或ECoG信号),应走专用路线,类似 AlphaFold。
- 对于文字相关的任务(例如,证明黎曼猜想),应走通用路线,类似那6个IMO金牌模型,而不应该再走 AlphaGeometry的专用路线。