Scaling Law 为何没有导致过拟合?
昨天给学生上课,讲到这张图:
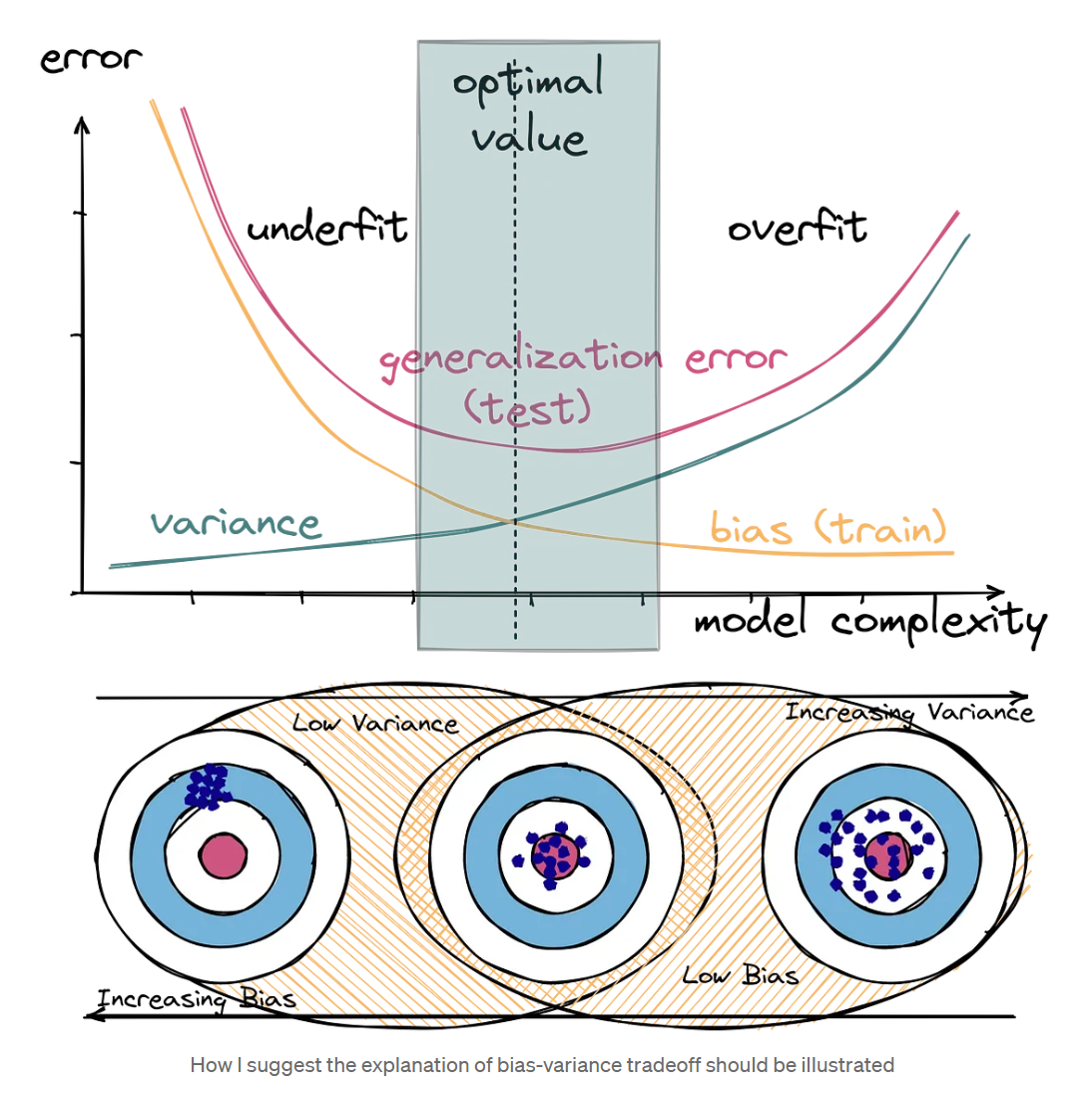
一个想法突然钻入我的脑海——在深度学习中,过去十年大家一直在拼命增加参数量,那为什么没有导致过拟合呢?
一个原因是——那是因为数据量也在上涨。但是,过去三年(2022-2024),互联网上所有的文本数据几乎都被拿来训练了,而人们还在拼命增加大语言模型的参数量,但是却并没有导致过拟合!
这有点不可思议。如果这张图是对的,那么在互联网上的文本数据都用了的情况下,增加参数量应该导致过拟合才对,即模型在新的数据上效果变差。
思来想去,我想到两个解释
- 这张图只适合传统机器学习,不适合深度学习。
- 这张图也适合深度学习,只不过我们还在前半段。
我个人更倾向于第二种解释。